
水ノ茉(こおり)の宣伝
叡智でえっちな同人作品を予定中…
Ci-en R18
同人作品の宣伝
プラグインの宣伝
始まり
こういう表現ができる内製クロスシミュレーションを作ったので紹介です。
お名前はReinPhysicsシリーズのReinClothちゃんです。
リポジトリ
ドキュメントは準備中…
クロスシミュレーションとは?
布っぽい動きをさせるための物理シミュレーションです。読んで字の如くです。
筆者でも分かるクロスシミュ
筆者は数学と英語、分かりません。特に数学。座学が大嫌い過ぎて、学がないのです。そんなバカでもステップごとに細分化して概略を理解すれば意外と組めるものです。極論、最初の頃はアルゴリズムの本質を理解できなくても、動けばいいのです。当然最初から理解できるに越したことはないし、理解できるひとが偉いんですけど、バカはバカなのです。このバカというのはバグではなく、仕様です。今更修正は出来ません。
というわけで、そんなバカアホでも理解できるクロスシミュの大まかな仕組みです。
1. 重力をかける
布に重力の影響を付与します。当然落下します。空気抵抗は存在しないのでシンプルな挙動です。布とは言っていますが、厳密には「布を構成する各頂点に重力の影響を付与」の方がイメージしやすいです。
2. ピン留め
布の端っこを固定します。クロスシミュ用語に置き換えると質量(Mass)をゼロにします。これで端っこ以外が落下します。
3. PBD(位置ベース物理)という基礎で至高の魔法
準備は整いました。残りは落下する挙動に対して、「現状の姿を保とうとする処理」を追加するだけです。
その処理にPBD(Position Based Dynamics)という物理の代表的なアルゴリズムを使うのです。
大雑把に正確性を削いでいうと、これは「2点間の距離を保つ処理」です。
- 離れたら引き戻す。
- 近づき過ぎたら突き飛ばす。
文面だけで見るとまるでメンヘラですが、あんな厄介な存在とは異なり、これは至高のアルゴリズムです。
例として端っこと、その隣を見ていきます。重力落下することで最初の頃の距離から徐々に離れていきます。これを引き戻し・引っ張ります。そして引っ張り続けると今度は初期の頃よりも近くなります。そしたら突き放します。
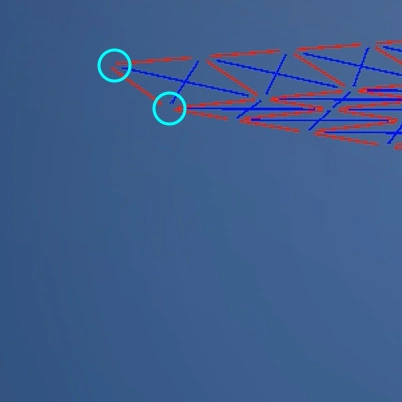
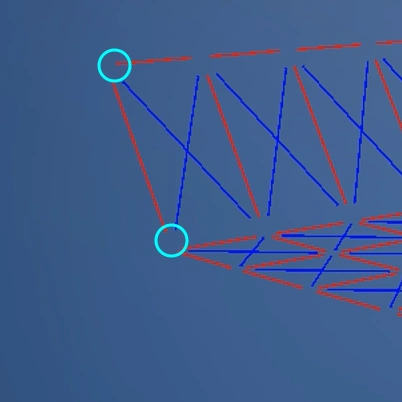
そして端っこの隣を動かすと、次は「端っこの隣」と「端っこの隣の隣」との距離が離れます。これも同様に引っ張ったり、突き放したりします。これの繰り返しです。
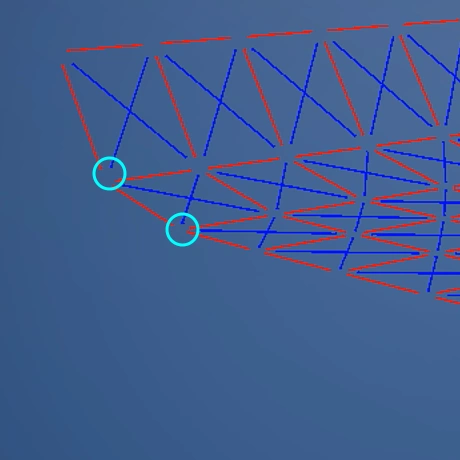
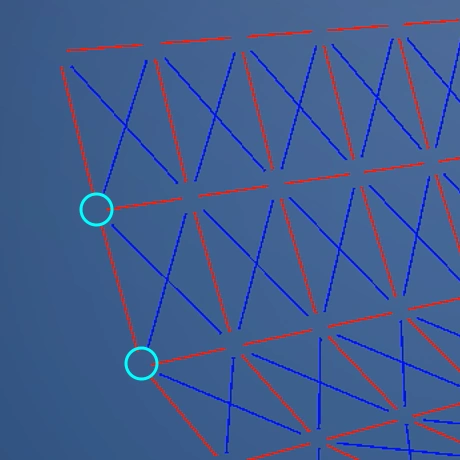
この計算を全頂点・全エッジ行うと、結果として「布っぽい挙動」を顕現させることができるのです。
分解してみると結構簡単でしょ?
こういう現実的な物理挙動を、リアルタイムにシミュレーションできる程度の粒度や領域まで落とし込んでくれている各界の天才たちに感謝ですね。
構造、せん断、曲げ
布の形状を維持するために、3種類のバネ(制約)を張ります。
構造(Structure)
縦横の伸び縮み

せん断(Shear)
斜め方向のひしゃげ防止

曲げ(Bending)
ひとつ飛ばしの隣との接続

各制約は単体では動画のように機械的な挙動や意味不明な挙動をしますが、それぞれが相互に作用することで布っぽい挙動・表現につながるのです。初めてBendingを単体で動作させましたが、デバッグ描画の方法も相まって本当に意味不明な挙動をしています。割と無視してください。
ワークフロー
大まかに3つのフェーズで計算します。
- PreSolve
- 重力やアニメ変位を付与して「仮の移動先」を決める
- SolveConstraints
- 制約に従って各頂点間の距離を保つ
- PostSolve
- 制約計算結果に基づいて最終的な位置を決定したり、コリジョンで当たり判定をしたりする
ガウス法とヤコビ法
PBDの解決方法には、ガウスとヤコビの2つの選択肢が存在します。
そもそも、なぜこの2つの選択肢が存在するのか。それは制約計算を並列処理する際の競合問題を考えると受け入れやすいです。
各制約は2つの頂点を参照したり、書き換えたりします。これらの制約は同じ頂点にアクセスすることが多々あります。丸で囲った頂点を例にすると、最大で12の制約が同じ頂点を指していることが分かります。
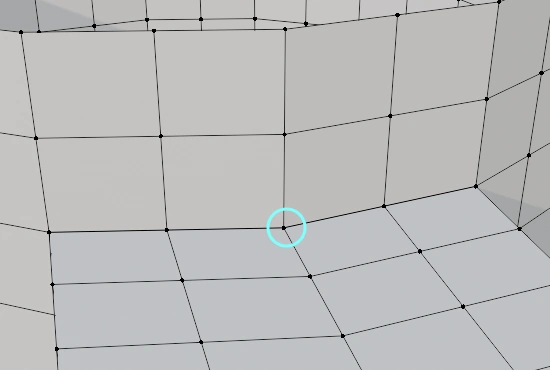
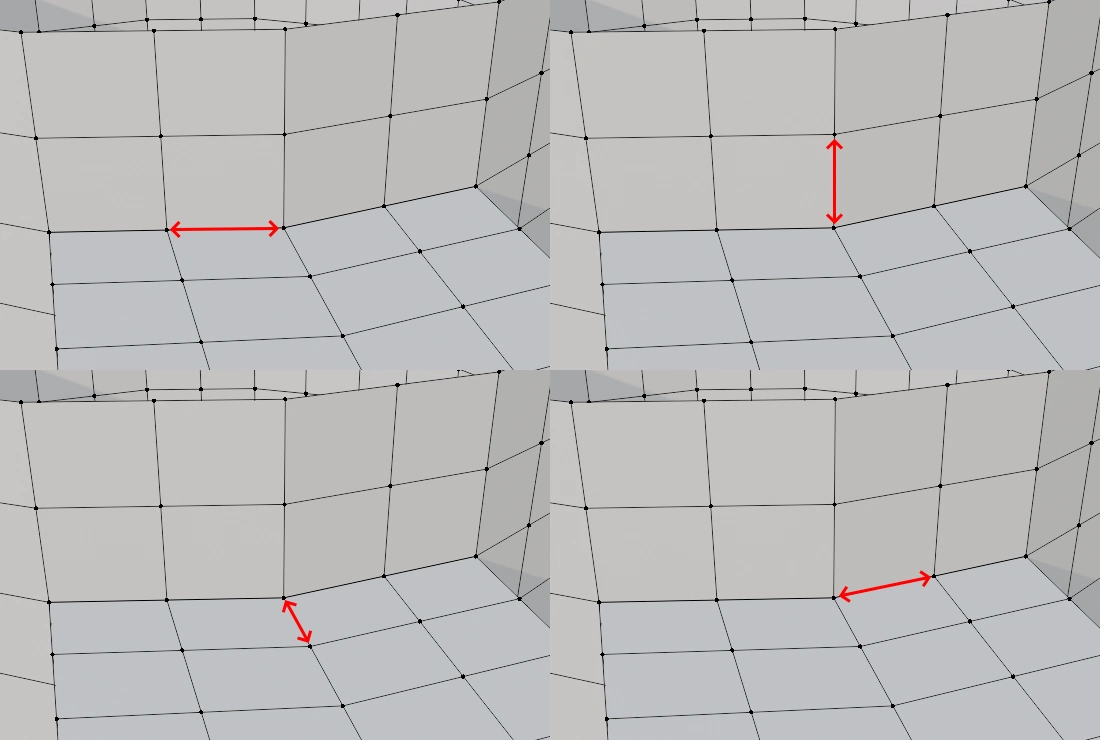
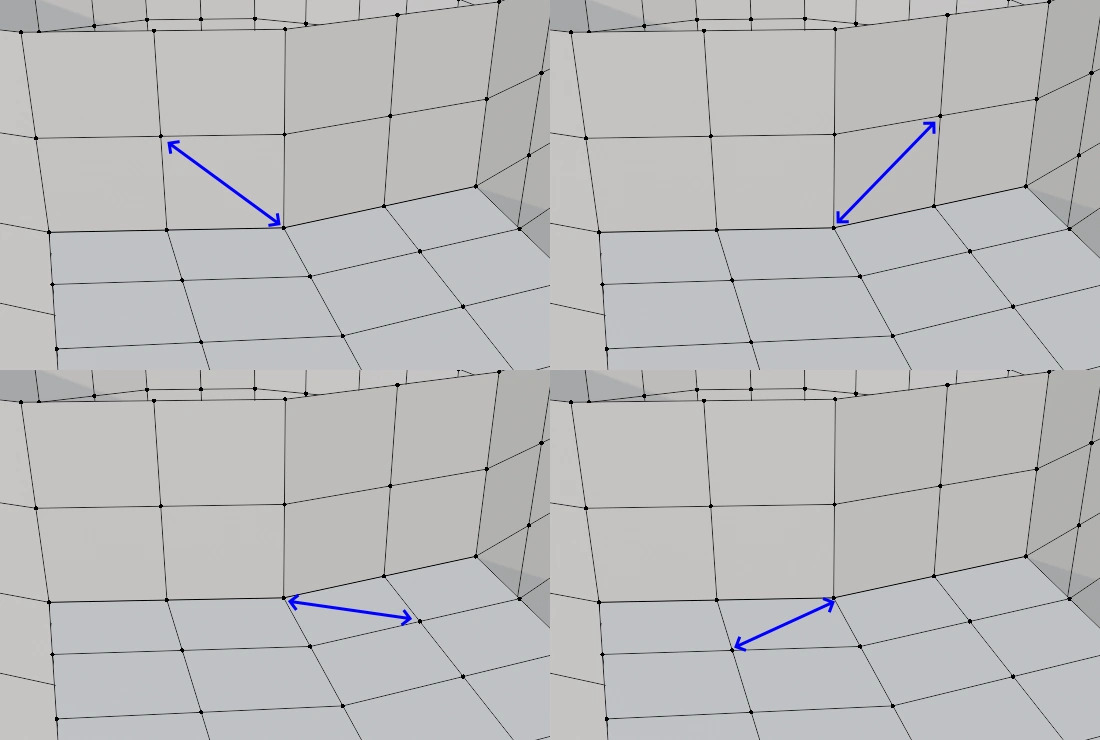

CPUでもGPUでも同じですが、並列処理する際に同じメモリにアクセスして書き換えることは厳禁です。これを解決するためにはLock(排他制御)が必要です。当然ですがLockにはコストが掛かります。
この競合問題の解決方法として、ガウスとヤコビという選択肢が存在するのです。
ガウス・ザイデル法
ガウス法は同じ頂点にアクセスしない制約同士をひとつのグループにまとめて、グループごとに処理をする手法です。このグループ分けをカラーリングと呼ぶことがあるため、赤色や青色などの色で説明されるケースが多いです。
グループ内では競合しないことが担保されているため、並列処理がロックフリーでも安全に実行出来るというわけです。
もうひとつの特徴として、後述のヤコビとは異なり計算結果を即時反映・更新するため、結果の収束が早いです。
欠点としてグループ分けの手間と、GPU設計を考えた際に愚直にやるとDispatchを量産してしまう点がネックになり得ます。
ヤコビ法
ヤコビは割と脳筋手法です。
まずは位置変数を2つに増やします。
最終的に確定した座標であるPositionと予測座標であるPredictの2つです。
- PreSolve
- 重力やアニメ変位を適用した場合の移動先をPredictに格納
- 制約が無ければ“ここまで移動するであろう”という意味合いの予測座標
- SolveConstraints
- Predictを参照しながら制約計算を進行
- 移動量はAtomicな別変数に書き込み
- PostSolve
- 最終的な移動量を取り出し、その結果を元にPositionを更新
読み込みはPredict、書き込みはAtomicな別変数、このように役割ごとに分離することで、ロック処理を比較的安価に抑えて並列処理をするという手法です。
ガウス法と異なりカラーリングは不要で愚直に回せるという手軽さを有しています。
ただし座標更新のタイミングがSolveConstraintsによる即時更新ではなく、PostSolveによる遅延更新となります。そのため結果の収束がガウスに比べて遅いです。場合によってはこの遅延更新が不安定な挙動につながることもあります。他にもアトミック操作はハード性能に大きく依存するという不安定さも抱えています。
CPUと相性の悪いクロスシミュ
負荷にまつわるお話です。
PBDの計算はかなり軽量です。頂点や制約単位で使用するものは四則演算と平方根、内積あたりの基本的な命令のみです。
ネックになるのは頂点と制約の物量です。頂点は数百から数千、制約は数千から数万に上ります。

CPUは「ひとつの重い処理」をすることは得意ですが、「たくさんの軽い処理」を並列に行うことは苦手です。クロスシミュは後者にあたるため、ハード設計的に相性が悪いのです。
ちなみにUnreal Engine標準のクロスシミュであるChaos ClothはCPU演算です。ISPCという低レベル・レイヤーな書き方をすることで頑張って最適化をしていますが、ハードウェア特性を逆転させるほどのものではないというのが現実です。前提としてChaosは「Physicsとの連携やマルチプレイ対応」という枷を背負わされているので、速度面はどうしても限界があります。UE4からUE5で、PhysXからChaosに置き換わった当初、かなり叩かれていましたよね。歴戦のPhysXと新参のChaosでは、どうあがいても勝てるわけ無いので、そもそも比べてあげるなよと内心思っていましたが、開発現場では負荷は忌むべき存在なので、仕方がないのでしょう。
GPUと相性のいいクロスシミュ
並列と相相がいい子といえばGPUです。物理や数学は分かりませんが、描画はある程度のナレッジを握っています。つまりわたしの戦闘領域です。
エンジン改造 vs プラグイン
総合的に見てどちらが優れているかに関しては、土俵が違うので明言は避けておきます。
事実として最適化ならエンジン改造が圧勝ですが、導入難易度や保守コストはプラグインが圧勝です。今回は広域的な展開を企んでいたため、プラグイン形式を採用しました。
制約構築
セットアップの容易さを完全に捨てて、シミュレーションメッシュを要求するスタイルを選択しました。以前にレンダーメッシュから三角形な制約を構築する手法を試したのですが、描画用の頂点数を流用してしまうと処理負荷に限界を感じたので、諦めて本方式としました。
胴体と腕などの接合部の曲げバネ構築だけ少し特殊ですが、無事に完了です。


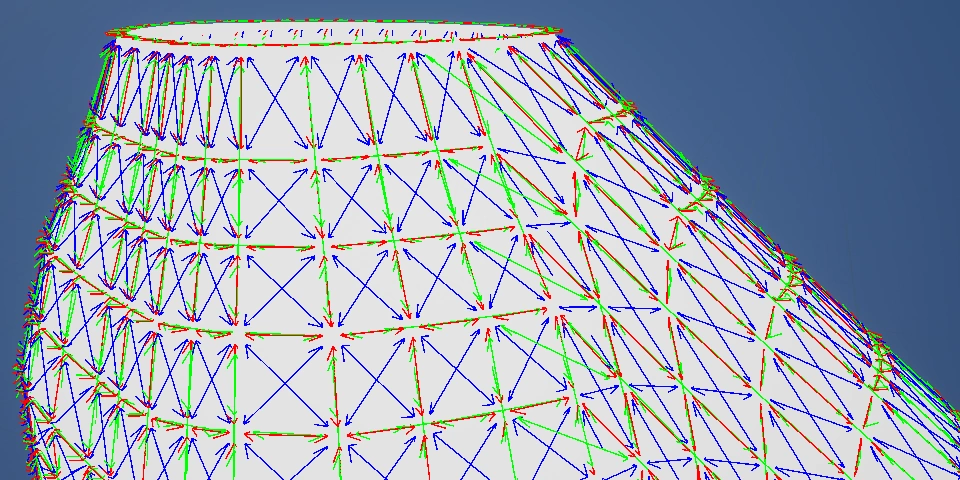
CPUなクロスシミュの作成
試作版は開発やデバッグ効率を重視してCPUで作成します。
採用するものはPBDとヤコビです。
XPBDは減衰の収束が早過ぎて理想とする揺れとは違ったので不採用としました。フレームレートやパラメタを考慮した際の安定性はXPBDに軍配が上がるのですが、動作フレームは最適化を極限まで頑張るので問題ないと仮定、パラメタは単純にして調整コストを抑える方針です。技術ベースで選択してもいいですし、作品に沿ったアルゴリズムを選択するのもいいでしょう。このあたりは開発者の好みだと思います。
最小構成
イテレーションは1回でサブステップ数をパラメタとするスタイルです。
コンプライアンスは小数だと表示限界があるため、剛性(Stiffness)をパラメタとして表示して、内部で流し込む際に1.0除算する方式を採用しています。

試作は無事に完了です。新しい制約構築も無事にハマりました。
コリジョン対応
GPU化する前に不備があったらデバッグが面倒なカプセルコリジョンを実装しておきます。
GPUなクロスシミュの作成
CPU版で基本的な動作は完了したので、GPUに移植していきます。
エンジンからプラグイン設計にダウングレード
初めてプラグイン設計なGPGPUを作りました。普段はエンジンを直に触っているのでとても新鮮な気持ちです。そしてやはり高レベル・レイヤーな実装は色々と劣りますね。全てのAPI、インターフェースにアクセスできるエンジン層と比べてしまうと、どうしても制限を感じます。とはいえプラグイン設計なGPGPUという意義は達成できたので目標達成です。
デバッグ描画機能
GPGPU化に伴いDrawDebug関数が使用できなくなったので、GPUパーティクルみたいな方法で描画するように変更しました。
void MainVS(in uint VertexID : SV_VertexID, out float4 OutPosition : SV_POSITION)
{
ResolvedView = ResolveView();
uint TriangleID = VertexID / 3;
uint ComponentID = VertexID % 3;
uint BatchIndex = TriangleSRV[TriangleID][ComponentID];


処理負荷の現実
サブステップあたりに PreSolve, SolveConstraints, PostSolve の3回ほどDispatchを叩いています。サブステップは大体5回ほど回しているためSolverだけで15回、その他のAnimationとEmbeddedを合わせると1回のシミュレーションに17回ほどDispatchを叩いていることになります。結果として相応に重いのです。
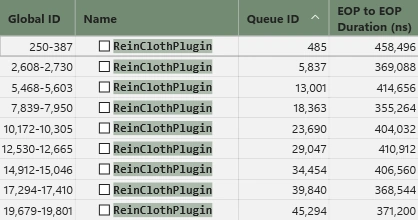
おそらくこの数値だとChaos Clothの方が早いまであります。知らんけど。GPUとクロスは理論上、相性がいいというだけで、組み方が下手だと、このように特性を殺してしまいます。少しずつ改善していきましょう。
ScatterからGatherに変更してみる
現状のSolveConstraintsは制約ベースのScatterを採用しています。もうひとつ頂点ベースのGatherというものがあります。
Scatterはスレッドあたりの計算量は最小なのですが、制約数からスレッド数を決定するため、スレッドが肥大化する傾向があります。対してGatherは頂点数からスレッド数を決定するため、スレッド数をかなり抑えられます。欠点はその頂点が影響を受ける制約をすべて計算する必要があるため、スレッドあたりの計算量が増加することです。
昨今のGPUはスレッドを大量に乱立させるより、1つのスレッドに大量の計算を詰め込んだ方が早いという噂があります。風の噂ですが、他にやることもないので試しに検証してみましょう。
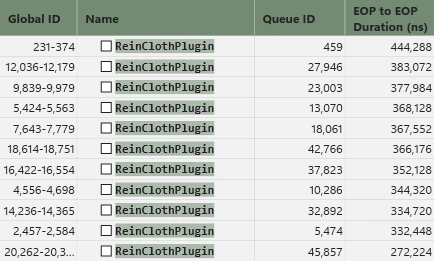
結果はご覧の通り、悪化しました。
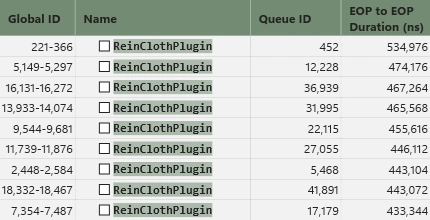
当てが外れて正直残念ですが、愚直にScatterからGatherに置き換えるだけでは負荷が却って伸びる、という知見を得られたことは収穫です。効果があること、ないことを片っ端から明確にしておくと、意外と今後に活きてくるのです。
PreSolve, SolveConstraints, PostSolveを統合してみる
試しにGatherを実装したことでSolverをすべて頂点ベースでまわすことが出来るようになりました。
さてと、先ほどの風の噂に、もう一度、賭けてみましょうか。
結果は50%ほど改善しました。賭けに勝ちました。
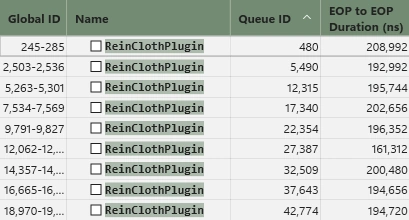
レイテンシ, ALU, ストールの改善
ダメ押しで低レベルな最適化をしていきます。
少しだけ小難しい用語が飛び交います。この手の用語は使わないとダメとかではなく、相手に正しく伝わるなら使った方が齟齬対策やコミュの短縮として有益です。ただし相手の理解度によってはかえって悪化するため、基本的には普通に説明した方が適切です。同業なんだから出来て当たり前という思考は悲しいけど意外と通用しないです。筆者も割と伝わらない方の部類なのであんまりトヤカク言うと跳ね返ってくるので止めておきます。
以下の説明は割とざっくりで且つ不正確な部分もあるかもなので、ニュアンス程度に受け取ってください。真面な説明は真面なサイトにお任せします。ここは実質的にエロサイトと遜色ないので、真面目と正確性は諦めてください。
- メモリ・レイテンシ(Latency)
- ざっくりいうとフェッチの待ち時間
- ALU(Arithmetic Logic Unit)
- 加減乗徐、行列計算などを担当している子
- ストール(Stall)
- 『レイテンシが詰まることでALUが遅延する』=『ストールする』みたいな感じ
// 位置座標をフェッチする
// フェッチが終わるまで待ち時間が発生する(レイテンシ)
float4 Position = PositionSRV[xxx];
// ここのALU(加算処理)はPositionのフェッチが完了しないと進行しない(ストール)
float4 NewPosition = Position + float4(1.0, 1.0, 1.0, 1.0);現状はPreSolve, SolveConstraints, PostSolveを愚直にひとつのシェーダーにコピペして動かしています。そのため、PositionやVelocityなどのフェッチタイミングがまちまちです。
// PreSolve
float4 Position = PositionUAV[xxx];
float4 Velocity = VelocityUAV[xxx];
// SolveConstraints
uint Start = OffsetSRV[xxx];
uint End = OffsetSRV[xxx + 1];
uint PackedData = NeighborSRV[xxx];
// PostSolve
FReinClothPluginInfluence Influence = InfluenceSRV[xxx];
float3x4 InvBoneMatrix = ComputeInvBoneMatrixWithLimitedInfluences(Influence.Bones, Influence.Weights);フェッチのタイミングがマチマチだと当然ストールが発生します。色々と細かいことをいうとレジスタとかメモリバスとか意味不明な用語が飛び交うと思いますが、それを概ね正しく説明出来る自信は無いので止めておきます。理解して書けるのと、それを他者に説明できるは、決してイコールではないのです。筆者は結構感覚派ですしおすし。
このストールがバカにならないのでこのように改善します。
// フェッチを極力冒頭にまとめる
float4 Position = PositionUAV[xxx];
float4 Velocity = VelocityUAV[xxx];
uint Start = OffsetSRV[xxx];
uint End = OffsetSRV[xxx + 1];
uint PackedData = NeighborSRV[xxx];
FReinClothPluginInfluence Influence = InfluenceSRV[xxx];
float3x4 InvBoneMatrix = ComputeInvBoneMatrixWithLimitedInfluences(Influence.Bones, Influence.Weights);
// 以降の PreSolve, SolveConstraints, PostSolve ではレイテンシが限りなく削減されるためALUがフルに動作して高速化につながる改善前は約195,000nsでしたが、改善後は約145,000nsまで短縮できました。
約50,000nsほどの削減ですね。
データ構造や処理を一切変えず、GPU設計に寄り添った書き方をするだけで、こんなにも簡単に負荷は変わるのです。だから最適化って面白いのです。
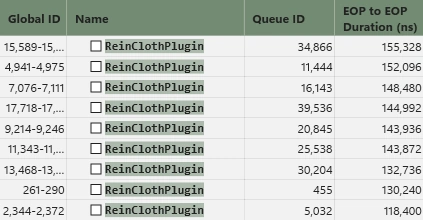
最終的な最適化の結果
遡って計測結果を取ってくることに限界を感じたので箇条書きにします。
- サブステップごとにDispatchを発行していた箇所を、1回のDispatchでサブステップも回すように変更
- この時点では統合型ソルバーは1回あたりの実行時間が約2,000nsほどのため、タイムアウトの懸念もないと判断
- アニメーションも同様に上記の統合型ソルバーに内包してDispatchを削減
- コリジョンまわりの行列計算の最適化
- 最終的にはシミュレーション1回あたり統合型ソルバーと埋め込みの2回のDispatchにまで削減
最終的な負荷はこんな感じになりました。
上から順に全体の負荷、クロスシミュの本体である統合型ソルバーシェーダー、クロス結果を描画メッシュに伝播するための埋め込みシェーダーです。
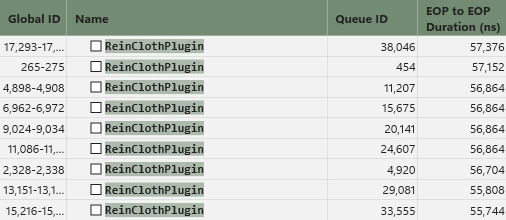
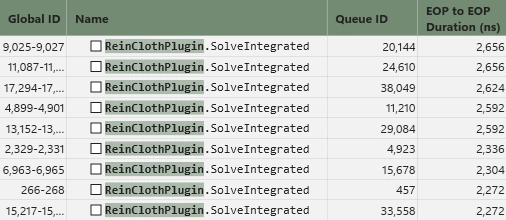
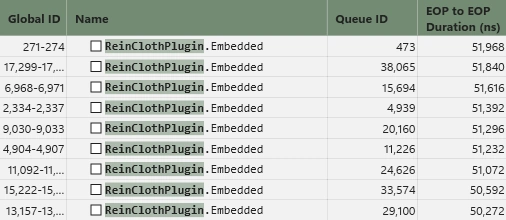
我ながら過去最高の成果物になりました。
クロス1回あたり約55,000nsほどで回せます。
しかも負荷のほとんどが埋め込みシェーダーで占めているというのが特徴的です。これはエンジンからプラグインにグレードダウンした際に直面する設計上の限界点です。汎用性を捨てればエンジンと近い環境を手に入れられるのですが、それは本末転倒なので素直に汎用を取った結果がコレです。つまりエンジン改造で組み込めば更に早くなる余地が残されているのです。
むふふ。
流石に実装当時はニヤニヤが止まりませんでしたね。
うれしい。マジで嬉しい。
内製開発の楽しさはこれです。
スコープ計測の信憑性に難あり
我慢できずにエンジン版を作成して計測したところ不可解な現象に遭遇しました。
こんな感じで髪の毛とスカートに設定しました。

SolverとEmbeddedの負荷が逆転することがありました。
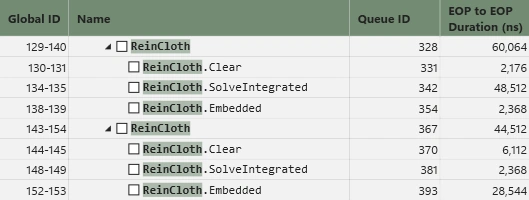
計測方法に誤りはないと思うため、とても腑に落ちません。ReinCloth全体の負荷に大きな乖離は見られなかったので、あくまでもスコープ内の計測結果に疑義があるという程度なのですが、ちょっとガッカリです。軽いという事実に変わりないのですけど、エンジンならもっともっと軽くなると見込んでいたので、ちょっと凹みました。
RDG_EVENT_SCOPE_STAT(GraphBuilder, ReinClothPluginEmbedded, "ReinClothPlugin.Embedded");
RDG_GPU_STAT_SCOPE(GraphBuilder, ReinClothPluginEmbedded);
or
RHI_BREADCRUMB_EVENT_STAT(RHICmdList, ReinCloth_Embedded, "ReinCloth.Embedded");
SCOPED_GPU_STAT(RHICmdList, ReinCloth_Embedded);おわり!!!
ふぅ。満足な出来です。
クロス開発はこれにてひと区切りですね。
我ながら『叡智とえっち』というフレーズが天才的過ぎます。
なんともわたしにピッタリ。
こういう些細なモチベは意外と大事なのです。
雑談
『R18な同人作品で使用する』という明らかに不純な理由で、狂ったほど軽量なクロスを生み出すという珍行為を無事に遂行できました。我ながら技術力が爆発する方向がアングラ過ぎるのです。でもこれがまた最高に趣味を謳歌してるって感じで心が満たされるのです。
出来ればロングスカートでもっとひらひらさせたかった。
その前に力尽きた。
この少しふわっとしてる感じ、本当に好き。

後日談
新しく記事を書くには、ボリュームが足りないけれど、この気持ちの発散先がほしい。
ということで後日談です。
計測方法の変更
PIXではなくUnreal Insightsで部分的に計測に変更です。
埋め込みを頂点ベースに変更
エンジンに組み込んだところ負荷が思いのほか改善しない珍事が起きました。そのため方針を切り替えてプラグイン版を更に最適化することにしました。
現状は統合ソルバーと埋め込みシェーダーの2回ほどDispatchを叩いています。埋め込み処理も統合ソルバーに合流させて更なる最適化を企てます。
Before

After

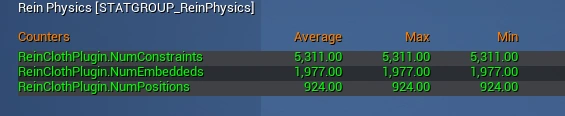
最終的な負荷
最終的な負荷はこんな感じです。
平均値としては45μs、0.045msほどです。
上から制約数(5,311)、描画頂点数(1,977)、シミュレーション頂点数(924)
プラグイン版
エンジン版

えっちな作品に留めておくには惜しいほど爆速になりました。たぶん早いはずです。地味にChaosClothもHavokも使ったことないので、比較対象をなにも知らない世間知らずです。
幅の大きい最適化はすべて完了
えちえちな同人作品をリリースするまでに競合プラグインが出ないことを祈ります。手法を公開しているので簡単に模倣できると思いますが、幸いにもここはアダルトサイトです。真面な開発者はおそらく辿り着けないことでしょう。そうであってほしいものです。
関係ないけどUnityでは需要あるのかな?
わたし、気になります。